

PythonでPDF→DOCXを一括変換できない?おすすめライブラリ&安全ツール決定版ガイド

概要
本記事では、Python PDF DOCX 変換を実現する方法を徹底解説します。pdf2docxやPyMuPDFといったPythonライブラリから、専用デスクトップツールまで幅広くカバー。バッチ処理スクリプト、OCR機能、自動フォルダ監視ソリューションなど、信頼性の高いドキュメントワークフローを構築するための必読情報をお届けします。


| 問題の種類 | 典型的な原因 | 事前チェック / 診断 |
|---|---|---|
スキャンPDF | 選択可能なテキストなし | PDFを開いてテキストをハイライトしてみます。何もハイライトされない場合は、OCRが必要です。 |
複雑なテーブル/レイアウト | pdf2docxにはレイアウトエンジンがありません | まず1ページを変換し、列のずれを確認します |
埋め込みフォント / 文字化け | フォントのサブセット化または非標準エンコーディング | DOCX内の□やランダムな記号をスキャンします |
大規模バッチのクラッシュ | メモリまたは依存関係の競合 | 5〜10ファイルでテストし、RAM使用量を監視します |

| アプローチ | 最適な用途 | 主な制限 |
|---|---|---|
pdf2docx | デジタルPDFの迅速な変換 | 複雑なレイアウトに弱い。OCRなし |
PyMuPDF + python-docx | 完全な制御とカスタム抽出ロジック | レイアウト再構築に大規模なコーディングが必要 |
pdfplumber | テーブル中心のPDF | DOCX出力なし。テキスト抽出のみ |
Pandoc | スクリプト可能なパイプライン。多形式ワークフロー | PDF→DOCXの品質はLaTeX/PDFリーダーに依存 |
LibreOffice CLI | バッチ自動化。ヘッドレス変換 | レイアウトの忠実度は変動。OCRなし |
| 機能 | サポート |
|---|---|
直接PDF→DOCX | はい |
OCR | いいえ |
埋め込みフォント | 部分的 |
複雑なレイアウト | 中程度 |
自動化 | はい |
XFAフォーム | いいえ |
| 機能 | サポート |
|---|---|
直接PDF→DOCX | いいえ(手動コーディング) |
OCR | いいえ(外部OCRが必要) |
埋め込みフォント | 読み取り専用 |
複雑なレイアウト | 高い制御、手動 |
自動化 | 優秀 |
XFAフォーム | いいえ |
| 機能 | サポート |
|---|---|
直接PDF→DOCX | いいえ |
OCR | いいえ |
埋め込みフォント | いいえ |
複雑なレイアウト | テーブルに強い |
自動化 | はい |
XFAフォーム | いいえ |
| 機能 | サポート |
|---|---|
直接PDF→DOCX | はい(LaTeX経由) |
OCR | いいえ |
埋め込みフォント | いいえ |
複雑なレイアウト | 限定的 |
自動化 | 優秀 |
XFAフォーム | いいえ |
| 機能 | サポート |
|---|---|
直接PDF→DOCX | はい |
OCR | いいえ |
埋め込みフォント | 部分的 |
複雑なレイアウト | 中程度 |
自動化 | 優秀 |
XFAフォーム | いいえ |

複数形式対応 Word/Excel/PowerPoint/テキスト/画像/HTML/EPUB
多機能PDF変換/暗号化/復号化/結合/透かし追加等。
OCR対応 スキャンされたPDF・画像・埋め込みフォントから文字を抽出
処理速度速い複数のファイルを同時に編集/変換できます。
対応OS Windows 11/10/8/8.1/Vista/7/XP/2000
多形式対応 Excel/Text/PPT/EPUB/HTML...
OCR対応 スキャンされたPDF・画像・埋め込みフォントから...
多機能PDF変換/暗号化/結合/透かし等。
主な利点
複数形式対応 Word/Excel/PowerPoint/テキスト/画像/HTML/EPUB
多機能PDF変換/暗号化/復号化/結合/透かし追加等。
OCR対応 スキャンされたPDF・画像・埋め込みフォントから文字を抽出
処理速度速い複数のファイルを同時に編集/変換できます。
対応OS Windows 11/10/8/8.1/Vista/7/XP/2000
多形式対応 Excel/Text/PPT/EPUB/HTML...
OCR対応 スキャンされたPDF・画像・埋め込みフォントから...
多機能PDF変換/暗号化/結合/透かし等。
手順
pip install pymupdf python-docx watchdog
import fitz # PyMuPDF
from docx import Document
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
import time
import os
class PDFHandler(FileSystemEventHandler):
def on_created(self, event):
if event.src_path.endswith('.pdf'):
self.convert_pdf_to_docx(event.src_path)
def convert_pdf_to_docx(self, pdf_path):
doc = fitz.open(pdf_path)
word_doc = Document()
for page in doc:
text = page.get_text()
word_doc.add_paragraph(text)
output_path = pdf_path.replace('.pdf', '.docx')
word_doc.save(output_path)
print(f"Converted: {output_path}")
if __name__ == "__main__":
path = "watch_folder" # Create this folder
if not os.path.exists(path):
os.makedirs(path)
event_handler = PDFHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
python pdf_to_docx_automate.py
制限事項
- 完全なコード制御とカスタマイズ
- シンプルなネイティブPDFに無料で使用可能
- 既存のPythonパイプラインへの容易な統合
欠点:
- スキャンドキュメント用の組み込みOCRなし
- 複雑なテーブルや画像が頻繁にずれる
- スケジュール実行に外部ツールが必要
- 異なるPDFレイアウトには大規模なデバッグが必要
| ユースケース | 推奨ツール |
|---|---|
1〜2のシンプルなPDFでクイックテスト | Python pdf2docxスクリプト |
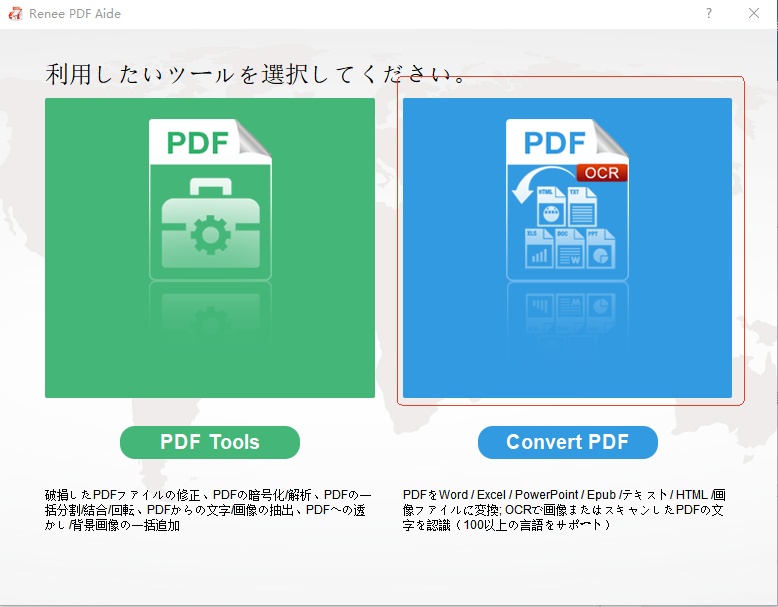
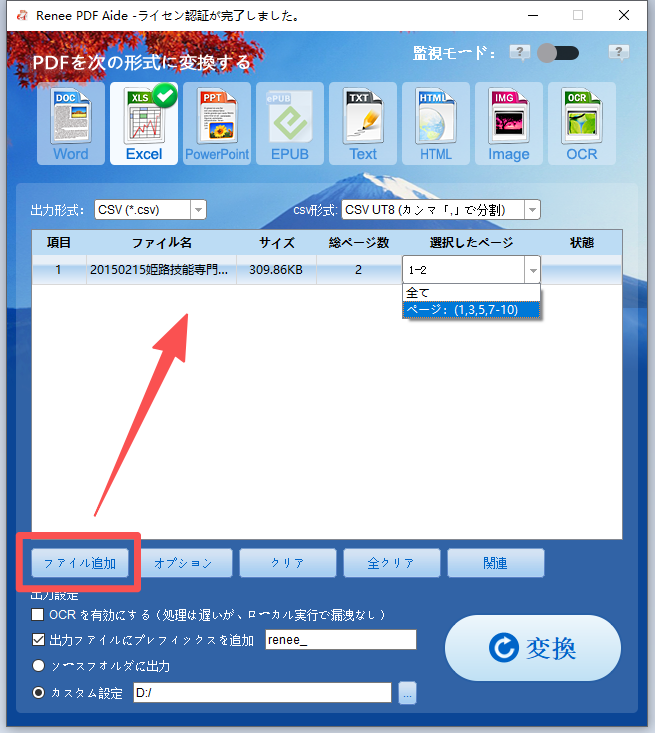
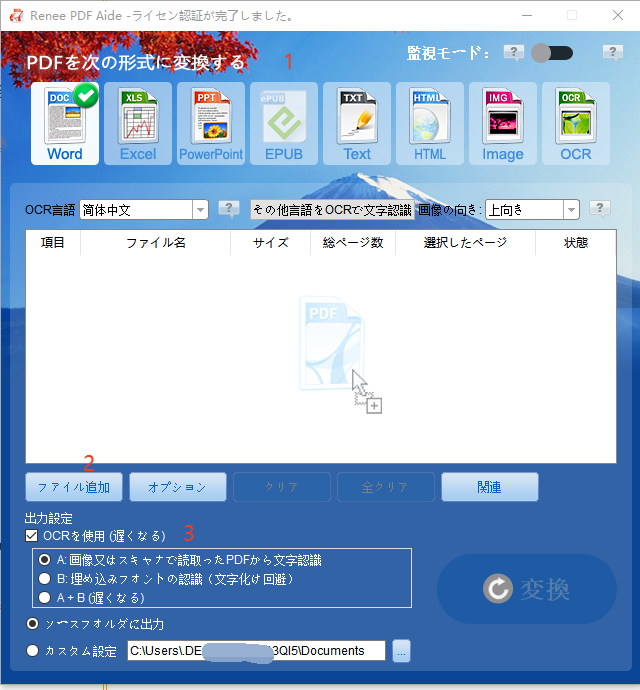
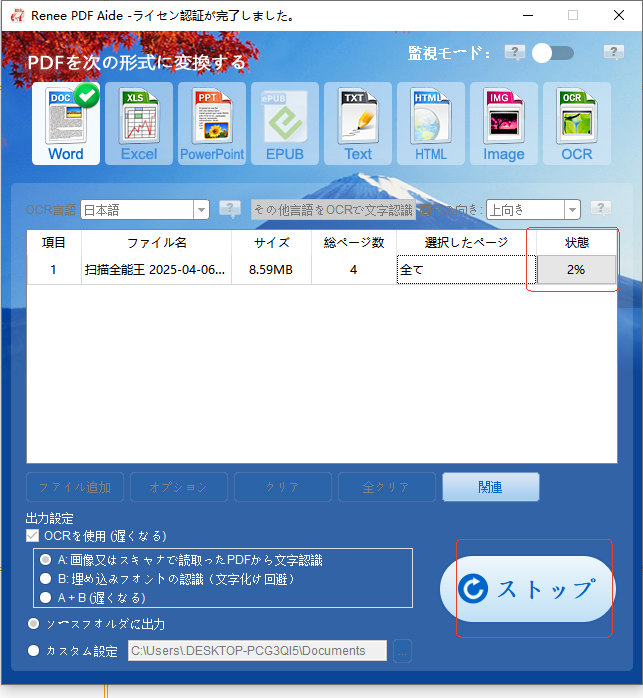
スキャンPDFまたは複雑なレイアウト | OCR搭載のRenee PDF Aide |
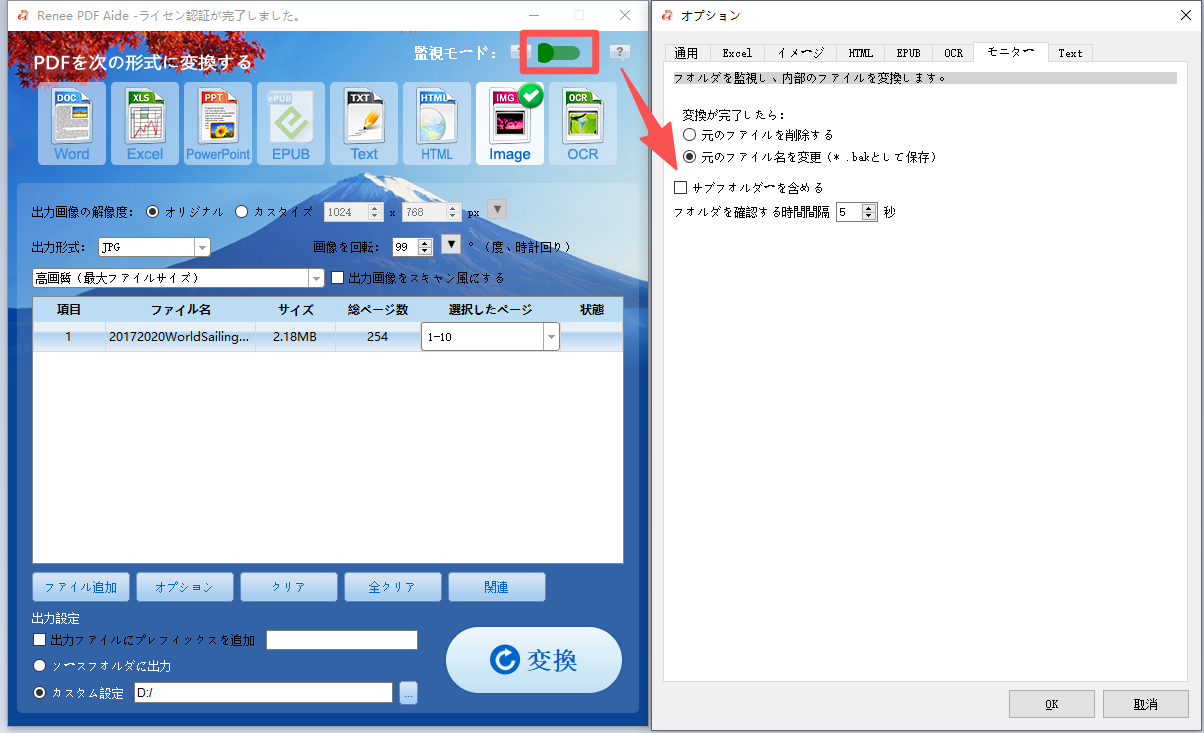
バッチ変換(50ファイル以上) | Renee PDF Aide(バッチ + 監視モード) |
定期夜間変換 | Renee PDF Aide監視モード |
完全なコード制御 + シンプルなPDF | PyMuPDF + watchdogカスタムスクリプト |
Pythonスクリプトで読み取れないスキャンPDFもRenee PDF Aideで処理できる?
pdf2docxでテーブルの書式や列の配置が崩れるのはなぜ?
Renee PDF Aideの最大バッチサイズやページ制限は?
PythonやRenee PDF Aideでパスワード保護されたPDFをDOCXに変換できる?
Renee PDF AideはXFAフォーム(銀行や政府のPDF)に対応している?

複数形式対応 Word/Excel/PowerPoint/テキスト/画像/HTML/EPUB
多機能PDF変換/暗号化/復号化/結合/透かし追加等。
OCR対応 スキャンされたPDF・画像・埋め込みフォントから文字を抽出
処理速度速い複数のファイルを同時に編集/変換できます。
対応OS Windows 11/10/8/8.1/Vista/7/XP/2000
多形式対応 Excel/Text/PPT/EPUB/HTML...
OCR対応 スキャンされたPDF・画像・埋め込みフォントから...
多機能PDF変換/暗号化/結合/透かし等。
関連記事 :

2025-10-28
Ayu : 2025年最新の無料ツールやAI技術を使い、PDFから表を正確かつ安全に抽出する方法を徹底解説。Excel・CSV・Markdo...

2025-10-03
Imori : 無料ツールとOCR技術を使って、PDFファイルからテキストを簡単に抽出する方法を学びましょう。このガイドでは、手動から自動化され...


ユーザーコメント
コメントを残す