

PDFの表抽出で困ったら?無料&AIツールで速攻解決!

概要
2025年最新の無料ツールやAI技術を使い、PDFから表を正確かつ安全に抽出する方法を徹底解説。Excel・CSV・Markdownなど、あらゆる形式への変換が可能。手間のかかる手作業はもう不要!今すぐ快適なデータ活用を始めましょう。



- Excel(*.xlsx)
- CSV(*.csv) (データベースやデータ分析に最適)
- Markdown (AI学習データやドキュメント作成に理想的)
- TXT ファイル
- 編集可能な Word 文書
- ……他にも多数の形式に対応。

多機能 XFA、マルチテーブル、スキャンされたPDFをOCR精度で簡単に変換
安全 100%ローカル変換でデータ漏洩のリスクゼロを保証
効率 数十のPDFファイルを数秒でバッチ処理
多様な形式に対応 PDFをExcel、PowerPoint、テキストなどにシームレスに変換
コスパ抜群 無制限のPDF2Word変換を無料でお楽しみください
多機能 XFA、マルチテーブル、スキャンされたPDFをOCR...
安全 100%ローカル変換でデータ漏洩のリスクゼロを保証
効率 数十のPDFファイルを数秒でバッチ処理
Renee PDF Aideで表を抽出する手順
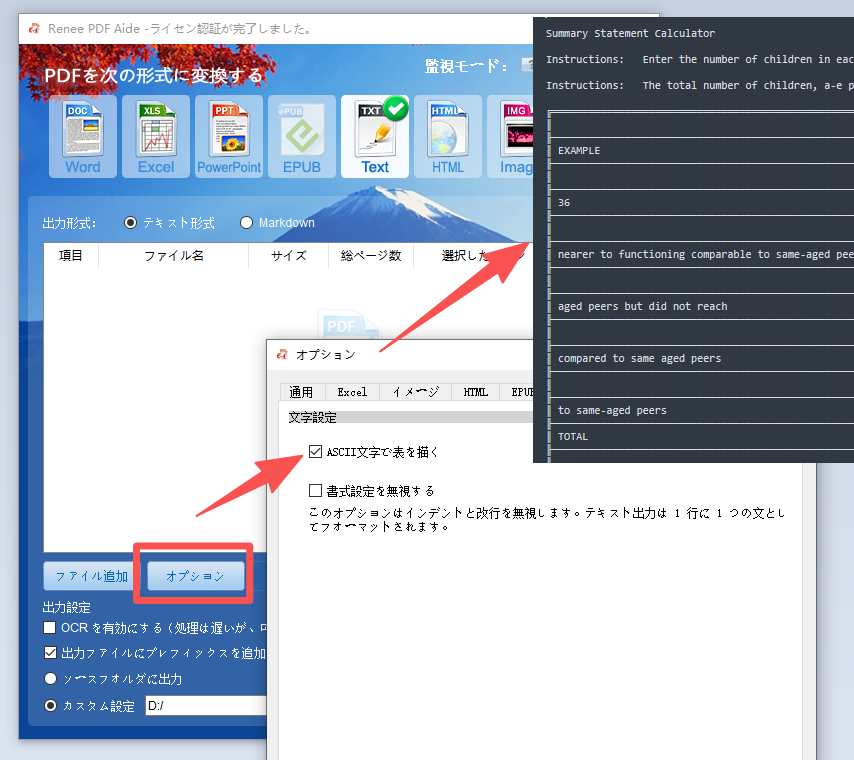
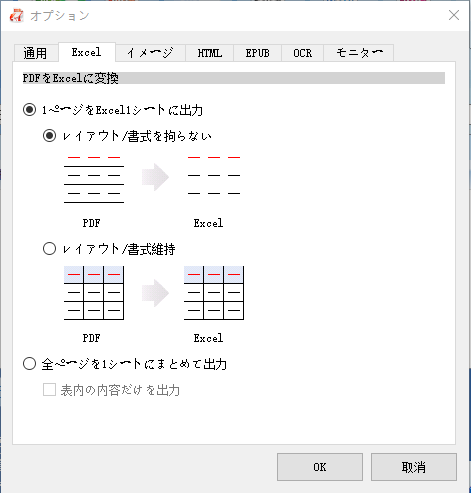
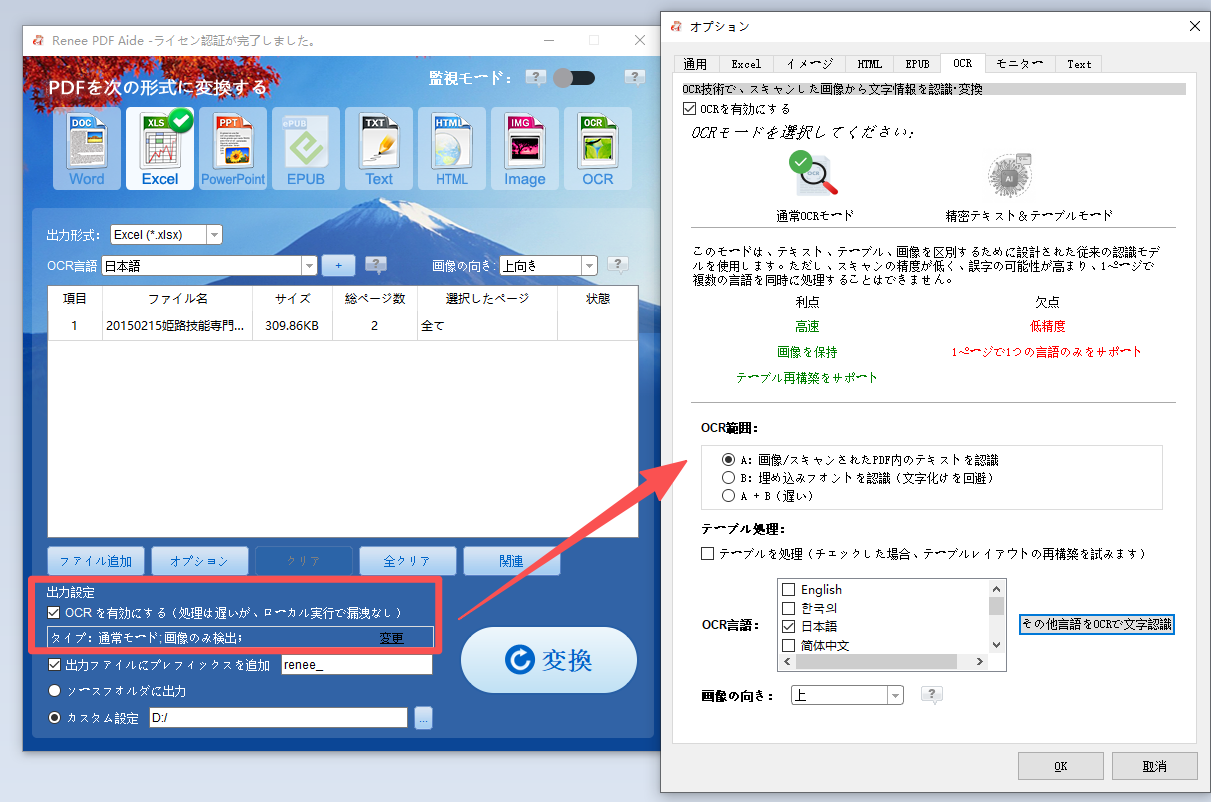
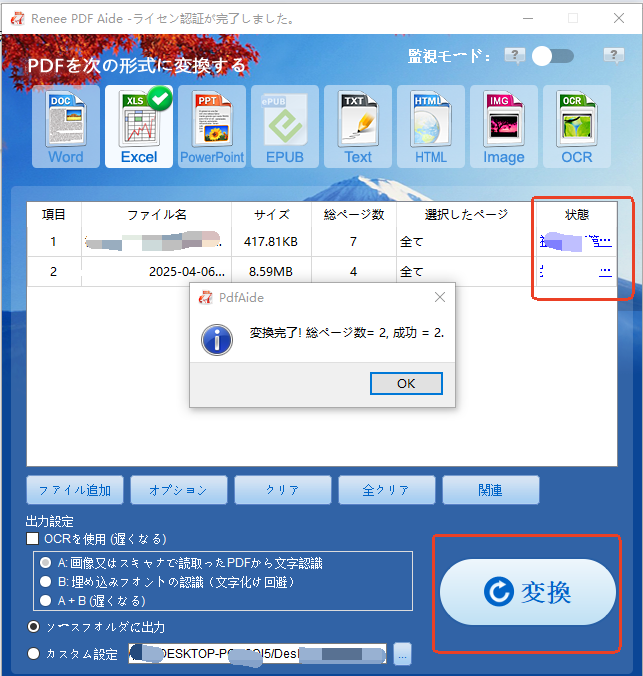
- 完全無料かつオープンソース。
- ローカルで動作し、データプライバシーを100%確保。
- 表を視覚的に選択できるシンプルなインターフェース。
- CSV形式でエクスポート可能(汎用性が高い)。
欠点:
- スキャンされた(画像ベースの)PDFには対応していません。
- 複雑な表や結合セル、特殊なレイアウトには対応が難しい場合があります。
- システムにJavaのインストールが必要です。
- 現在は積極的にメンテナンスされておらず、バグ修正が行われない可能性があります。
Tabulaで表を抽出する手順:


「PDFをエクスポート」機能を使えば、PDF内の表を整形された Excel(XLSX)ワークブック や Word文書 に直接変換でき、元のスタイル・フォント・レイアウトを驚くほど正確に再現します。これは、精度とAdobe製品との連携が重要な企業環境での定番ですが、高額な サブスクリプション料金 がネックです。
- ネイティブPDF・スキャンPDFのどちらに対しても極めて高い精度を実現。
- Excelへのエクスポート時に優れた書式保持性能。
- 完全なPDF編集スイートの一部(テキスト・画像の編集なども可能)。
- 大手企業による信頼性とサポート体制。
欠点:
- 非常に高価(月額または年額サブスクリプションが必要)。
- 表抽出だけが目的なら、機能がオーバースペック。
- 操作が複雑で、リソースを多く消費する(大容量のプログラム)。
Adobe Acrobat Proで表を抽出する手順:

- 難解なスキャンや低画質スキャンでも、業界最高水準のOCR精度を実現。
- 複雑な表構造の再構築に優れる。
- 多数の言語をサポート。
- 数千ページものバッチ処理に対応可能。
欠点:
- プロフェッショナル向けの高価格設定。
- 完璧な結果を得るには、カジュアルユーザーにとっては設定が複雑な場合がある。
- 高度なOCR解析のため、処理に時間がかかる。

ABBYY FineReaderで表を抽出する手順:
- ドラッグ&ドロップで極めて簡単。
- インストール不要。ブラウザがあればどのデバイスでも利用可能。
- シンプルな変換なら非常に高速。
- 多くのサービスが、たまに使うユーザー向けに無料プランを提供。
欠点:
- 重大なプライバシーリスク:文書を第三者のサーバーにアップロードする必要あり。
- 複雑な表やスキャンPDFには対応できないことが多い(OCR機能付きの有料プランなら可能)。
- 無料版には制限あり(ファイルサイズ・ページ数・1日あたりの利用回数など)。
- 安定したインターネット接続が必要。
📊 PDFからMarkdown表への変換:ツール比較
| PDF入力対応 | スキャン画像OCR | 無料プランの制限 | 有料プランのメリット | |
|---|---|---|---|---|
| Copilot | ✅ スクリーンショットのみ(PDFの直接アップロード不可) | ✅ 画像入力によるOCR対応 | ⚠️ 1回のメッセージにつき1枚の画像のみ。PDFアップロード不可 | ✅ 画像入力無制限。処理が高速で、書式の再現性も向上 |
| ChatGPT | ✅ PDFおよび画像入力対応(GPT-4oのみ) | ✅ 高性能OCRとレイアウト解析 | ⚠️ GPT-3.5のみの場合、画像・PDFの入力非対応 | ✅ GPT-4oで画像・PDF入力対応。OCR性能と書式再現性が強化 |
| Grok | ✅ スクリーンショットまたは貼り付けたコンテンツ対応 | ✅ Grok 3でOCR性能が向上 | ✅ x.com/appでGrok 3を無料利用可能(クォータ制) | ✅ Grok 3/4の有料プランでは、拡張メモリ(128Kトークン)、音声アクセス、画像生成モデル(Imagine)、AIコンパニオン(Ani & Valentine)が利用可能。ThinkおよびDeepSearch機能に代わる |
- 画像ベースのPDFや表のスクリーンショットを扱っている場合。
- 書式を維持したいが、Excelを使いたくない場合。
- Markdownベースのドキュメントやウェブサイトに直接表を埋め込みたい場合。
AIツールで表を抽出する手順:
- 無限のカスタマイズ性と強力な処理能力。
- 大規模バッチ処理の自動化に最適。
- 大規模なデータ分析パイプラインに統合可能。
- 多くのライブラリが無料かつオープンソース。
欠点:
- 高度な技術力とプログラミングスキルが必要。
- 特定のPDFレイアウトに合わせて設定・デバッグするのに時間がかかる。
- PDFのレイアウトが少し変わっただけでスクリプトが動作しなくなる可能性がある。
多機能 XFA、マルチテーブル、スキャンされたPDFをOCR精度で簡単に変換
安全 100%ローカル変換でデータ漏洩のリスクゼロを保証
効率 数十のPDFファイルを数秒でバッチ処理
多様な形式に対応 PDFをExcel、PowerPoint、テキストなどにシームレスに変換
コスパ抜群 無制限のPDF2Word変換を無料でお楽しみください
多機能 XFA、マルチテーブル、スキャンされたPDFをOCR...
安全 100%ローカル変換でデータ漏洩のリスクゼロを保証
効率 数十のPDFファイルを数秒でバッチ処理

PDFから表をコピー&ペーストすればいいのでは?
スキャン(画像)PDFから表を抽出する最良の方法は?
オンラインPDF表抽出ツールは安全ですか?
1つのPDFファイルから複数の表を同時に抽出できますか?
ネイティブPDFとスキャンPDFの違いは何ですか?
PDFの表に結合セルや複雑なヘッダーがあります。どのツールが最適ですか?
多機能 XFA、マルチテーブル、スキャンされたPDFをOCR精度で簡単に変換
安全 100%ローカル変換でデータ漏洩のリスクゼロを保証
効率 数十のPDFファイルを数秒でバッチ処理
多様な形式に対応 PDFをExcel、PowerPoint、テキストなどにシームレスに変換
コスパ抜群 無制限のPDF2Word変換を無料でお楽しみください
多機能 XFA、マルチテーブル、スキャンされたPDFをOCR...
安全 100%ローカル変換でデータ漏洩のリスクゼロを保証
効率 数十のPDFファイルを数秒でバッチ処理
関連記事 :
スキャンPDFをExcelに変換する完全ガイド:簡単・高精度なデータ抽出法

2025-04-24
Imori : この記事では、効率的なデータ管理を実現するために、スキャンされたPDFをExcelに変換する重要性を解説します。スキャンされたP...
PDFテキストの批量抽出:Excelへのスムーズ変換を可能にする簡単ガイド

2025-04-24
Satoshi : この記事は、PDFからExcelへのテキストデータ抽出に関する包括的なガイドを提供し、コスト、効率、正確性のバランスを取る際の課...
「Googleスプレッドシートを使ってPDFをExcelに変換する究極のガイド」

2025-04-18
Yuki : この文章では、Googleスプレッドシートを活用してPDFをExcelファイルに変換する効果的な方法について説明しています。PD...
2025-04-17
Ayu : この記事では、PDFからExcelに表データをインポートするための包括的なガイドを提供しています。さらに、より高度な変換や一括処...


ユーザーコメント
コメントを残す