

簡単にPDF ファイルからテキストを抽出する方法

概要
無料ツールとOCR技術を使って、PDFファイルからテキストを簡単に抽出する方法を学びましょう。このガイドでは、手動から自動化された手法までを網羅し、「PDFテキスト抽出」の疑問を解決する実践的な解決策を提供します。
さらに、日常の業務や学習で役立つTipsを追加して、効率アップのヒントをお届け。続きを読んで、時間を大幅に節約しましょう!



ページごとにテキストをコピー&ペーストする手順


PDFテキストをコピーすると文字化けが発生
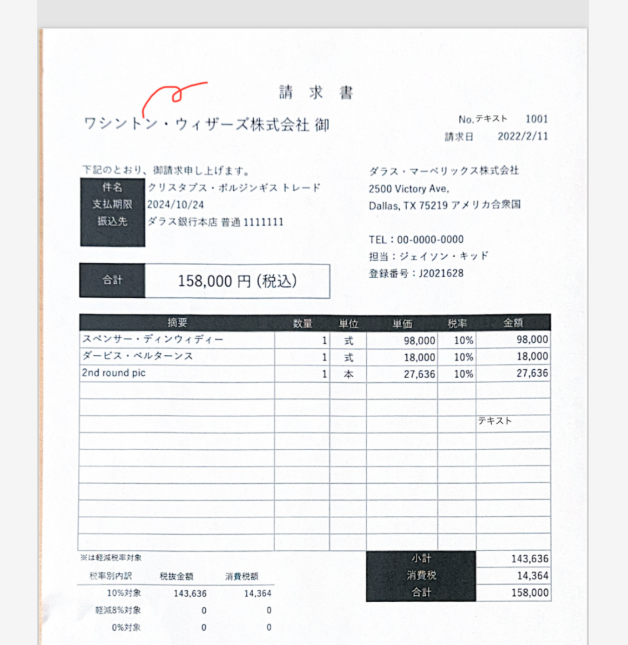
スキャンされたPDFファイル

複数形式対応 Word/Excel/PowerPoint/テキスト/画像/HTML/EPUB
多機能PDF変換/暗号化/復号化/結合/透かし追加等。
OCR対応 スキャンされたPDF・画像・埋め込みフォントから文字を抽出
処理速度速い複数のファイルを同時に編集/変換できます。
対応OS Windows 11/10/8/8.1/Vista/7/XP/2000
多形式対応 Excel/Text/PPT/EPUB/HTML...
OCR対応 スキャンされたPDF・画像・埋め込みフォントから...
多機能PDF変換/暗号化/結合/透かし等。
AIを使ってテキストを抽出する方法
Extract all text from this image as a bullet list.
Extract all text from this pdf file.
多くの場合、ユーザーはページごとに手動でスクリーンショットを撮る必要があり、時間がかかりエラーが発生しやすいです。大規模な作業やプロフェッショナル用途では、専用のデスクトップソフトウェアがより信頼性が高く効率的な選択肢です。
📊 PDF処理:無料プラン vs. 有料プラン(2025年更新)
| プラットフォーム | 無料版 | 有料 / プレミアム版 | PDF変換サポート | 出力形式 | 2025年 AI-OCR強化 |
|---|---|---|---|---|---|
マイクロソフト コパイロット | 最大50ページのPDFアップロード;大容量ファイルを分割。Edgeと統合でクイックOCR。 | Microsoft 365:無制限ページ、AI搭載の表抽出。 | ❌ 直接変換なし、API経由でJSONにエクスポート。 | プレーンテキスト、JSON | Cognitive Services v3.1:スキャンドキュメントで98%精度。 |
チャットGPT (オープンAI) | 直接アップロードなし;テキスト貼り付けまたはスクリーンショット。 | Plus/Team:最大300ページアップロード;画像の自動OCR。 | ❌ 要約のみ;エクスポートにプラグイン使用。 | プレーンテキスト、箇点リスト | LlamaParse統合:多言語PDF(例:英語+ヒンディー語)を扱う。 |
Grok(xAI) | 約50ページアップロード;テキストのセマンティック検索。 | Premium:約200ページ、バッチ処理。 | ❌ プレーンテキストのみ。 | プレーンテキスト | 低品質スキャンの強化OCR;プライバシー重視。 |
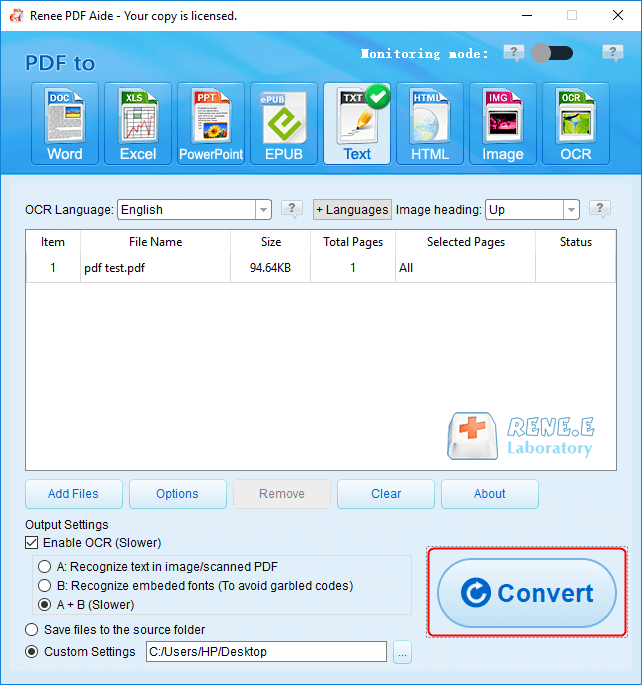
Renee PDF Aideとは?
複数形式対応 Word/Excel/PowerPoint/テキスト/画像/HTML/EPUB
多機能PDF変換/暗号化/復号化/結合/透かし追加等。
OCR対応 スキャンされたPDF・画像・埋め込みフォントから文字を抽出
処理速度速い複数のファイルを同時に編集/変換できます。
対応OS Windows 11/10/8/8.1/Vista/7/XP/2000
多形式対応 Excel/Text/PPT/EPUB/HTML...
OCR対応 スキャンされたPDF・画像・埋め込みフォントから...
多機能PDF変換/暗号化/結合/透かし等。
テキストをWordに抽出
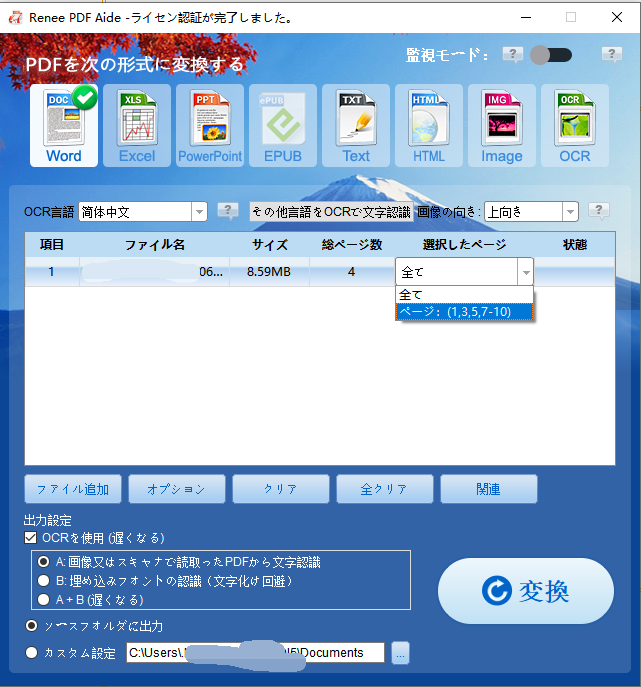
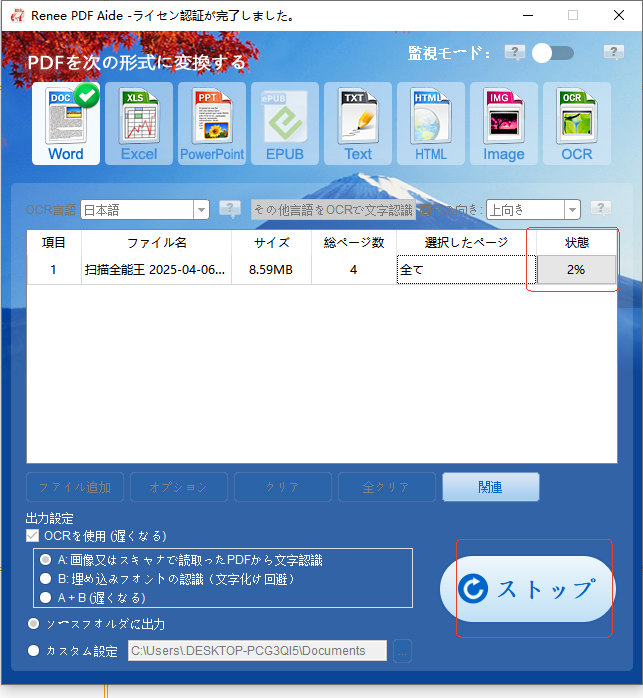
テキストをExcelに抽出
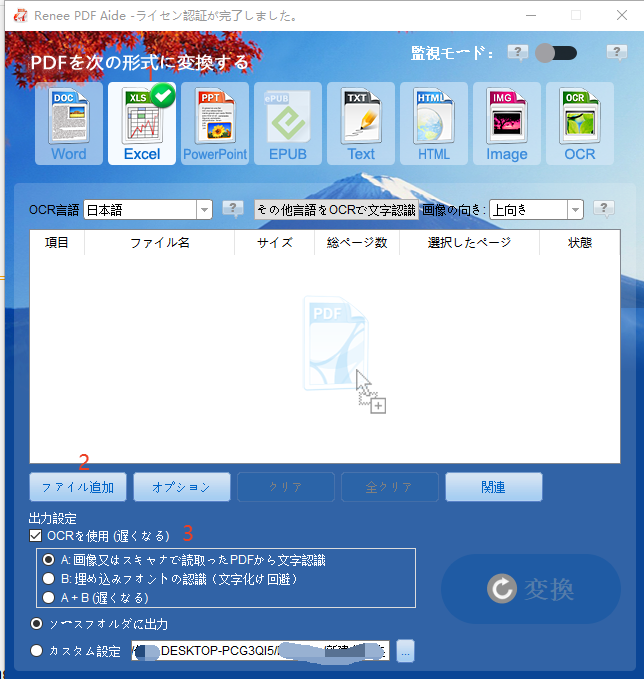
テキストをPowerPointに抽出
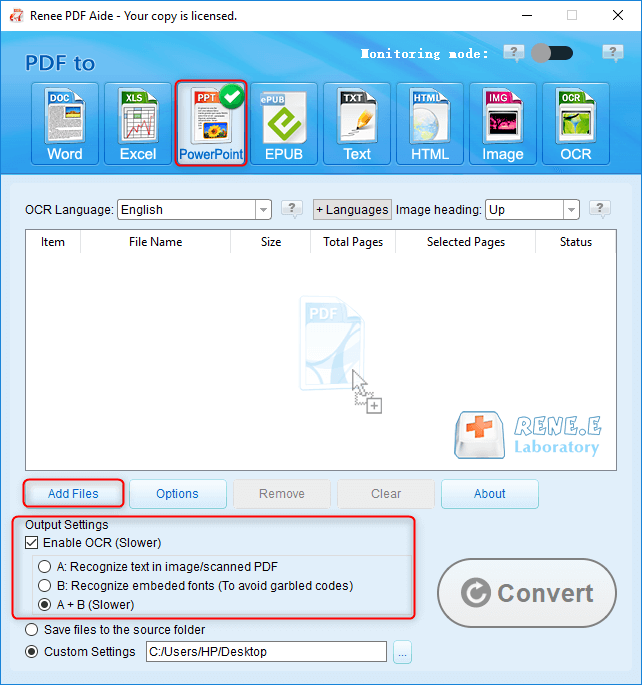
テキストをTXTに抽出

| ツール | 機能 | 制限 |
|---|---|---|
PDF Candy | 無料PDF-to-TXT変換、スキャンファイルの自動OCR、ユーザー friendlyインターフェース。カタログから製品リストを抽出するのに理想的。 | ファイルサイズ制限(約100MB)、無料版の広告、ピーク時の遅延、サーバーアップロードによるプライバシーリスク。 |
PDF2Go | 登録不要、モバイル対応、OCR付きの高速TXT変換。会議PDFからのクイックノートに最適。 | ファイルサイズ制限、潜在的なデータ露出、時折のフォーマット損失、インターネット必要。 |
Pythonスクリプト例
pip install PyMuPDF tesserocr python-docx Pillow
import os
import fitz # PyMuPDF
import pytesseract
from PIL import Image
from docx import Document
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def extract_text_to_file(pdf_path、 output_format="txt"、 lang="eng"):
try:
doc = fitz.open(pdf_path)
text_output = 「」
for page_num、 page in enumerate(doc、 start=1):
text = page.get_text().strip()
if text:
text_output.append(f"--- Page {page_num} ---\n{text}\n")
else:
pix = page.get_pixmap()
img = Image.frombytes("RGB"、 「pix.width、 pix.height」、 pix.samples)
ocr_text = pytesseract.image_to_string(img、 lang=lang)
text_output.append(f"--- Page {page_num} (OCR) ---\n{ocr_text}\n")
doc.close()
output_file = f"{os.path.splitext(pdf_path)「0」}.{output_format}"
full_text = "\n".join(text_output)
if output_format == "txt":
with open(output_file、 "w"、 encoding="utf-8") as f:
f.write(full_text)
elif output_format == "docx":
docx = Document()
docx.add_paragraph(full_text)
docx.save(output_file)
else:
raise ValueError("Unsupported output format. Use 'txt' or 'docx'.")
return output_file
except Exception as e:
print(f"Error processing PDF: {e}")
return None
if __name__ == "__main__":
pdf_file = "sample.pdf"
result = extract_text_to_file(pdf_file、 output_format="txt"、 lang="eng+hin")
if result:
print(f"Text extracted to: {result}")✅ 利点:無料、カスタマイズ可能
❌欠点:セットアップが必要
hin+engに設定して正確なOCRを実現。プレーンテキスト用にTXT、フォーマット編集用にWordとして保存。| ユーザー種別 | 最適方法 | 利点 | 次のアクション |
|---|---|---|---|
初心者 | コピー&ペーストまたはオンラインツール | シンプル、コストやスキル不要。 | 今日Foxit ReaderでPDFを開く。 |
プロフェッショナル | Renee PDF Aide | Word/Excelへの高速変換、セキュアオフライン。 | 公式サイトからトライアルをダウンロード。 |
テックサビー | OCR付きPython | 自動化、大規模データにスケーラブル。 | 依存関係をインストールしてコードをテスト。 |
モバイルユーザー | AIアシスタント | インターネットがあればどこでも機能。 | アップロード用にChatGPT Plusを試す。 |
抽出されたテキストが文字化けしたり不完全な場合どうする?
オンラインツールは機密PDFに安全か?
暗号化されたPDFからテキストを抽出できるか?
大容量PDF(例:500ページ以上)をどう扱う?
多言語PDFからテキストを抽出するには?
hin+eng)して二言語PDFから正確に抽出。テキスト抽出は元のPDFフォーマットを保持するか?
関連記事 :
PDFテキストの批量抽出:Excelへのスムーズ変換を可能にする簡単ガイド

2025-04-24
Satoshi : この記事は、PDFからExcelへのテキストデータ抽出に関する包括的なガイドを提供し、コスト、効率、正確性のバランスを取る際の課...

2025-10-03
Ayu : 無料ツールとOCR技術を使って、PDFファイルからテキストを簡単に抽出する方法を学びましょう。このガイドでは、手動から自動化され...
2024-03-12
Ayu : PDFドキュメントはユーザーが読んで使用することを目的としており、テキストを直接抽出することはできません。しかし、次の記事ではP...
2021-10-11
Ayu : PDFからテキストを抽出するための超簡単無料な方法を紹介します。紹介されたツールはOCR機能もついているので、スキャナで作成した...


ユーザーコメント
コメントを残す